- românesc
-
EnglishDeutschItaliaFrançais한국의русскийSvenskaNederlandespañolPortuguêspolski繁体中文SuomiGaeilgeSlovenskáSlovenijaČeštinaMelayuMagyarországHrvatskaDanskromânescIndonesiaΕλλάδαБългарски езикGalegolietuviųMaoriRepublika e ShqipërisëالعربيةአማርኛAzərbaycanEesti VabariikEuskeraБеларусьLëtzebuergeschAyitiAfrikaansBosnaíslenskaCambodiaမြန်မာМонголулсМакедонскиmalaɡasʲພາສາລາວKurdîსაქართველოIsiXhosaفارسیisiZuluPilipinoසිංහලTürk diliTiếng ViệtहिंदीТоҷикӣاردوภาษาไทยO'zbekKongeriketবাংলা ভাষারChicheŵaSamoa日本語SesothoCрпскиKiswahiliУкраїнаनेपालीעִבְרִיתپښتوКыргыз тилиҚазақшаCatalàCorsaLatviešuHausaગુજરાતીಕನ್ನಡkannaḍaमराठी
Programarea FPGA Xilinx și fluxul de design Vivado explicat
Catalog

Explorarea tutorialelor FPGA Xilinx
Lucrul cu FPGAs poate părea mai dificil din punct de vedere mental decât software-ul la început, parțial pentru că scopul nu este să execuți instrucțiuni, ci să descrii structuri hardware care funcționează simultan. Ajungi să te gândești la concurență, reguli de ceas, comportamentul resetării și dacă rapoartele de temporizare sunt de acord cu ceea ce credeai că ai construit. Atunci când oamenii devin frustrați devreme, adesea nu este din lipsă de efort, ci pentru că prea multe părți mobile se schimbă între încercări, iar cauza eșecului devine enervant de alunecoasă.
O modalitate constantă de a avansa este să repeți același flux de lucru până devine suficient de familiar încât greșelile să iasă în evidență. Păstrează o placă Xilinx bine suportată pe birou, începe cu un design HDL mic, simulează-l până când formele de undă au sens, rulează sinteza și implementarea în Vivado, programează dispozitivul și apoi confirmă comportamentul pe pini reali. Deși acest proces poate părea repetitiv, ajută la reducerea incertitudinii cu privire la dacă o problemă este cauzată de codul de design, constrângeri sau configurația plăcii, făcând depanarea mai eficientă.
În învățarea zilnică, partea abruptă a curbei se grupează de obicei în jurul câtorva abilități care se întăresc reciproc: utilizarea disciplinată a fluxului Vivado, scrierea Verilog-ului sintetizabil care se aliniază așa cum te aștepți și depanarea decalajelor inevitabile dintre simulare și placa fizică cu o metodă în care ai încredere. Dacă tratezi fiecare construcție ca pe un experiment controlat, schimbi o variabilă, observi efectul și notezi ceea ce ai văzut, vei observa că petreci mai puțin timp ghicind și mai mult timp formând instincte de încredere.
Folosește fluxul de proiect în Vivado într-un mod care rămâne stabil în timp
Vivado se comportă mai puțin ca un simplu buton de compilare și mai mult ca un pipeline care transformă RTL într-un design plasat și rutat care trebuie să trăiască în realitățile electrice și temporale ale plăcii. Mulți începători descoperă, uneori pe calea cea grea, că multă corectitudine trăiește în afara HDL: constrângerile, definițiile de ceas, standardele I/O și setările uneltelor pot decide în liniște dacă hardware-ul se comportă așa cum a promis simularea.
Un flux curat începe prin menținerea configurației proiectului modeste și repetabile, astfel încât să poți spune când ai îmbunătățit realmente designul față de când ai schimbat accidental mediu.
Alege o placă suportată și rămâi cu ea suficient de mult timp pentru a construi o intuiție pe care o poți reutiliza. Plăcile cu documentație solidă și designuri de referință tind să reducă anxietatea de fundal, deoarece poți verifica pinout-ul, ceasurile și presupunerile de putere fără a căuta postări neoficiale pe forumuri.
Începe cu un modul de vârf care produce rapid un rezultat vizibil. Ac feedback imediat te ajută să validezi că ceasul funcționează, pini sunt mapati corect și bitstream-urile sunt generate așa cum crezi că sunt.
Exemple de comportament observabil la nivel de top:
• Un LED care clipește
• Un echo UART
• Un contor care controlează GPIO
O obișnuință practică este să standardizezi un mic șablon de nivel superior devreme. De exemplu, păstrează un singur input de ceas, o abordare de reset pe care o înțelegi și un mic pachet GPIO consistent. Când scheletul rămâne același de la un proiect la altul, îți poți concentra atenția asupra logicii noi în loc să re-derivezi fundamentale de fiecare dată, ceva ce poate părea obositor și surprinzător de predispus la erori.
Constrângerile sunt o parte esențială a designului FPGA mai degrabă decât un pas final de ajustare. Multe probleme timpurii de hardware apar chiar și atunci când designul RTL este corect, deoarece constrângerile de ceas lipsesc sau sunt incorecte, pinii sunt asignați necorespunzător sau standardele de I/O nu se potrivesc cerințelor efective ale plăcii.
Un flux de lucru concret care te ține sincer este să definești ceasurile în XDC, să mapezi porturile folosind XDC-ul principal al furnizorului ca referință și apoi să verifici standardele de I/O față de schema plăcii. Acest proces poate părea puțin birocratic la început, dar tinde să înlocuiască suspiciunea vagă cu fapte verificabile.
Închiderea temporizării nu este rezervată doar pentru designuri rapide. Chiar și logica care pare lentă pe hârtie poate avea un comportament prost dacă instrumentul deduce relații de clocking neintenționate sau dacă semnalele asincrone sunt tratate în mod casual. A te obișnui să citești rapoartele de temporizare devreme poate reduce acel sentiment neplăcut de „Sper că este în regulă” când designurile devin mai mari.
Vivado îți spune constant ce părere are despre designul tău; partea dureroasă este că este ușor să dai clic peste avertizări și apoi să petreci ore întregi depanând o problemă care a fost deja descrisă pe consolă. În timp, oamenii care se mișcă mai repede sunt adesea cei care își dezvoltă un obicei calm de a verifica rapoartele după fiecare execuție, chiar și atunci când se așteaptă ca totul să fie bine.
După fiecare execuție de sinteză/implementare, păstrează aceste categorii de raport împreună pe propria linie de verificare:
• Starea temporizării și căile critice
• Utilizarea resurselor (LUT/FF/BRAM/DSP) față de așteptări
• Rezultatele inferenței (pentru RAM-uri, blocuri DSP și alte structuri intenționate)
Când o avertizare este prezentă încă din prima construcție, tinde să apară în cele mai ciudate eșecuri ulterior. O postură productivă este să presupui că avertizările merită atenție până când poți explica, în termeni pur ingineresti, de ce sunt benigne pentru designul tău specific.
Scrie Verilog sintetizabil care se potrivește curat pe hardware FPGA
Lucrul în HDL este mai aproape de designul circuitelor decât de dezvoltarea aplicațiilor, iar această schimbare poate fi emoțional perturbatoare: poți scrie Verilog valid care se simulează splendid și totuși se sintetizează într-un ceva mai lent, mai mare sau pur și simplu diferit decât ți-ai imaginat. Scopul este de a descrie structuri pe care FPGA le poate implementa în mod previzibil: flip-flopuri, logică LUT, BRAM și blocuri DSP, astfel încât comportamentul și temporizarea să se alinieze cu intenția ta.
Când mapparea este previzibilă, depanarea se simte mai puțin ca o ceartă cu instrumentul și mai mult ca o rafinare a designului.
O bază confortabilă pentru mulți începători este un singur domeniu de ceas cu logică sincrona simplă. Folosește blocuri always clocked pentru starea secvențială și asocieri continue (sau blocuri combinate scrise corect) pentru căile combinate. Crearea unei logici „asemănătoare ceasului” în fabrică poate funcționa în cazuri de nișă, dar tinde să invite riscuri legate de domeniul ceasului, cu excepția cazului în care deja înțelegi activarea ceasului, rutarea și implicațiile temporizării.
Comportamentul de reset este un alt loc unde alegerile mici pot crea rezultate surprinzător de inconsistente pe placă. Resetele asincrone pot fi utile, dar pot produce, de asemenea, riscuri de deasertare sau sensibilitate la diferențele de alimentare ale plăcii. Multe designuri FPGA folosesc resete complet sincrone sau aserțiune asincronă cu eliberare sincrona, deoarece aceste abordări ajută la reducerea comportamentului inconsistent de pornire în timpul testării de aducere în funcțiune.
Logica FPGA se bazează în mod natural pe conducte și structuri paralele. O dezamăgire comună a începătorilor este așteptarea unei execuții pas cu pas, asemănătoare software-ului, apoi simțind confuzie când totul se întâmplă simultan. O lentilă mai utilă este să decizi ce îți pasă pentru un bloc dat și apoi să proiectezi explicit pentru acel rezultat.
O lentilă de design pe un singur rând pentru performanță și mappare:
• Rata de transfer (iteme pe ceas)
• Latenta (cicluri de la input la output)
• Preferința pentru mapparea resurselor (LUT-uri vs BRAM vs DSP)
De exemplu, un multiplicator-acumulativ poate deduce feliile DSP în mod curat, dar schimbările minore de stil de codare pot îndrepta instrumentul către aritmetica bazată pe LUT. Când utilizarea te surprinde, adesea merită să te oprești și să pui o întrebare ușor incomodă: ai descris efectiv structura hardware pe care o intenționai sau ai descris ceva echivalent funcțional care costă mai multe resurse?
Simularea va accepta cu bucurie construcții pe care hardware-ul real nu le poate implementa așa cum ai putea imagina. Menținerea limitelor tale sintetizabile clare reduce încrederea falsă și face rezultatele simulării mai portabile pe placă.
Modele comune de păstrat grupate pe o singură linie ca o amintire rapidă:
• Evitați întârzierile (#) în logica sintetizabilă
• Nu depindeți de inițializare decât dacă ați confirmat comportamentul dispozitivului/unelui
• Fiți atenți la latch-uri neintenționate din asocieri combinatorii incomplete
• Folosiți sincronizatoare corespunzătoare pentru treceri între domenii de ceas
O obișnuință care tinde să fie benefică este să scrieți testbenches mici, auto-verificabile, care validează presupunerile pe care sunteți tentat emoțional să le ignorați: comportamentul resetării, rollover-ul contorului, protocoalele de handshake și condițiile limită. Când proiectele cresc, aceste teste devin mai puțin ca un lucru suplimentar și mai mult ca ceea ce vă împiedică să reconsiderați totul.
Debugați sistematic cu simulare și vizibilitate pe cip (ILA)
Chiar și simularea excelentă nu promite un comportament corect al plăcii. Hardware-ul real aduce jitter de ceas, întârzieri I/O, stări inițiale necunoscute și intrări asincrone care nu se aliniază politicos la marginea ceasului dumneavoastră. Cei mai rapizi debuggeri nu sunt, de obicei, cei care fac modificări aleatoare, ci cei care îngustează problema prin observație structurată și pot explica ce dovezi le-au schimbat părerea.
Un testbench puternic verifică comportamentul pe parcursul multor cicluri și nu evită scenarii incomode. Dacă modelați stimuli realiști, simularea devine un loc unde construiți încredere, nu doar un loc unde observați un semnal variază și sperați că înseamnă ceva.
Stimuli realiști care tind să expună logica fragilă:
• Bounce-ul butoanelor
• Erori de cadru UART
• Presiune inversă în interfețe de streaming
• Secvențe de resetare cu temporizare awkward
De asemenea, ajută să separați bug-urile în două categorii astfel încât să nu urmăriți un tip greșit de soluție:
• Bug-uri funcționale: logica RTL este greșită
• Bug-uri de integrare: RTL-ul este în regulă, dar ceasurile/resetările/ constrângerile/presupunerile I/O sunt greșite
Simularea este excelentă pentru a scoate la iveală bug-urile funcționale; testarea plăcii are un mod de a revela bug-uri de integrare în care nu ați vrut să credeți că sunt posibile.
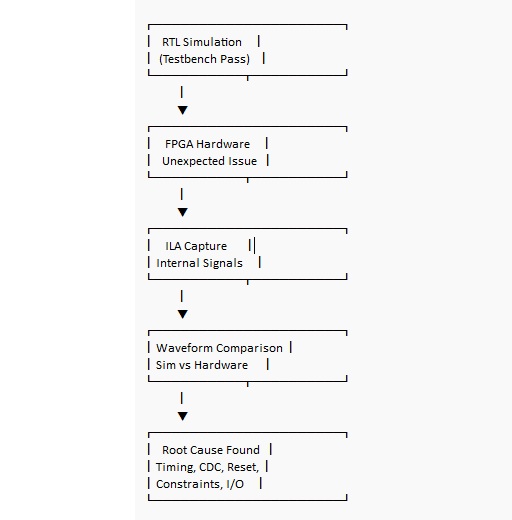
Când comportamentul hardware-ului nu coincide cu testbench-ul dumneavoastră, Analizorul Logic Integrat (ILA) este adesea cea mai directă modalitate de a înlocui speculația cu un traseu pe care îl puteți studia. Probați semnalele care reprezintă decizii și limite în interiorul designului, apoi capturați momentul în care lucrurile deviază și comparați-l cu forma de undă a simulării așteptate.
Semnalele care tind să fie sonde de mare valoare:
• Codificările stărilor FSM
• handshake-uri valide/preparate
• steaguri FIFO pline/goale
• ieșirile sincronizatorului de resetare
Un flux de lucru practic este să începeți cu mai puține sonde și o fereastră de captură mai largă. Pe măsură ce învățați unde se află eșecul, puteți strânge declanșatorul și adăuga detalii. Suprasaturarea cu instrumente poate reduce marja de temporizare și complica construcțiile, așa că este adesea mai sănătos să tratați inserția ILA ca un pas de măsurare concentrat mai degrabă decât ca ceva pe care îl păstrați "în caz de".
Unele dintre cele mai educaționale eșecuri apar atunci când simularea arată fără defecte, iar placa este instabilă. Această nepotrivire poate părea descurajantă, dar este și locul în care intuiția FPGA devine mai ascuțită, deoarece soluția se află de obicei în ceasuri, constrângeri sau igiena semnalului mai degrabă decât în algoritm.
Cauze comune ale divergenței între simulare și placă:
• Constrângeri de ceas lipsă sau incorecte
• Metastabilitate din intrări nesincronizate
• Variabilitate în temporizarea eliberării resetării pe cip
• Probleme CDC între mai multe domenii de ceas
• Diferențe în condițiile inițiale
O perspectivă care tinde să accelereze învățarea este să tratați temporizarea și observabilitatea ca proprietăți pe care le construiți deliberat în design. Când proiectele dumneavoastră mici definesc explicit ceasuri, constrâng I/O, sincronizează trecerile și expun semnale interne pentru măsurare, petreceți mai puțin timp sperând că funcționează și mai mult timp făcând îmbunătățiri controlate și explicabile. Această mentalitate se scalează natural de la un LED care clipește la conducte, interfețe și sisteme încorporate mai mari pe același dispozitiv.
Xilinx (AMD) vs. Altera (Intel) FPG
Xilinx (AMD) și Intel (Altera) vă livrează ambele familii de FPGA care arată comparabile pe hârtie, și este ușor să te simți încrezător după un scan rapid al fișei tehnice. Starea de spirit tinde să se schimbe mai târziu, când realitățile ingineriei de zi cu zi încep să decidă ritmul: comportamentul uneltelor pe dispozitivul dumneavoastră exact și gradul de viteză, dacă IP-ul pe care ați presupus că puteți folosi este de fapt licențiat în organizația dumneavoastră, dacă un design de referință se aliniază cu ceasurile și resetările dumneavoastră și dacă închiderea temporizării rămâne constantă odată ce designul devine de calitate de producție.
Un proces de selecție se desfășoară mai bine atunci când tratați FPGA ca un sistem de livrare, dispozitiv + unelte + IP + plăci + documentație + întreținere pe termen lung, deoarece acolo echipele câștigă impuls (și somn) sau acumulează anxietăți liniștite legate de program.
| Caracteristică |
Xilinx (AMD) |
Intel (Altera) |
| Poziția pe piață |
Istoric, lider pe piață, cunoscut pentru portofoliul său larg de produse și pentru faptul că este prima companie care lansează noi tehnologi. |
Competitor puternic, în special puternic în aplicațiile de centre de date și rețele, valorificând abilitățile de fabricație ale Intel. |
| Arhitectură de bază |
Logica se bazează în principal pe tabele de căutare cu 6 intrări (LUT-uri), oferind granularitate și flexibilitate ridicată. |
Folosește module logice adaptative (ALM-uri), care sunt mai complexe și pot fi configurate ca LUT-uri mai mari, îmbunătățind potențial densitatea logică pentru anumite proiecte. |
| Suita software |
Vivado Design Suite și Vitis Unified Software Platform. Adesea apreciată pentru interfața sa prietenoasă utilizatorilor experimentați. |
Quartus Prime Design Suite. Unii utilizatori consideră că interfața sa grafică este mai intuitivă pentru începători și este cunoscută pentru timpii mai rapizi de compilare în anumite scenarii. |
| Familii high-end |
Versal ACAPs (Platforme de Accelerare Adaptivă a Calculului) combinând motoare scalare, adaptabile și inteligente. |
FPGAs Agilex, cunoscute pentru performanță ridicată și eficiență energetică, cu unele benchmark-uri care arată un avantaj de performanță-per-watt. |
| Accent pe ecosistem |
Accent puternic pe integrarea procesorului și FPGA, așa cum se observă în familia Zynq. Populare pentru dezvoltarea aplicațiilor. |
Foarte potrivite pentru proiectele System-on-Chip și aplicațiile industriale, cu un portofoliu IP puternic pentru rețelistică și RF. |
Definirea selecției folosind constrângeri verificabile, nu așteptări de marcă
Începeți cu cerințele pe care le puteți testa devreme, nu cu impresii din proiectele anterioare. Obiectivul este de a reduce „surprizele în săptămâna 10”, care este locul unde frustrarea și reconfigurarea tind să se acumuleze.
Lista de verificare a constrângerilor:
• Resurse logice: LUT-uri/ALM-uri, registre, disponibilitate de rutare și plafon de utilizare așteptat
• Resurse DSP: numărul de blocuri, moduri de precizie, pre-adderi, opțiuni de cascadă/topologie și comportamentul de mapare pentru nucleele dvs. matematice
• Memorie pe cip: BRAM/URAM (sau echivalente M20K), capacitatea totală, moduri de port, lățimea de bandă pe ciclu, și tipare de contestație
• I/O de mare viteză: clasa SERDES, numărul de lane-uri, rata maximă a liniei, opțiuni pentru ceasul de referință și suport pentru protocoale legate de cazul dvs. de utilizare
• Memorie externă: variante DDR3/DDR4/LPDDR, maturitatea controlerului, comportamentul de calibrare și presupunerile de marjă SI la nivel de placă
• Latentă și determinism: țintă de la cap la cap, buget pe etape, toleranța la jitter și strategia CDC (inclusiv modul în care se traversează domeniile resetările)
• Envelope de putere/termo: estimări de comutare în cel mai rău caz, moduri de putere ale transceiverelor, presupuneri de răcire, și intervalul ambiental
Proiectele reale FPGA arată adesea că adaptarea în cadrul dispozitivului nu garantează o funcționare de înaltă viteză fiabilă. Proiectele care par acceptabile la o utilizare de 70–80% pot deveni instabile după adăugarea logicii de debug, protecția CDC, FIFOs, gestionarea erorilor și marja de sincronizare necesară pentru funcționarea practică.
Dacă echipa dvs. a pierdut vreodată o săptămână din cauza congestiei de rutare, apelul de a trece la o dimensiune mai mare a dispozitivului este ușor de înțeles. Trecerea de costuri nu este de obicei liniară: o parte ușor mai mare poate oferi sincronizare mai calmă, mai puține iterații ale instrumentelor și mai puține reconstrucții târzii.
Tratați fluxul de instrumente ca pe o cerință pe care nu o puteți scăpa
Fluxul de instrumente tinde să fie separatorul ascuns între un plan care pare solid și un plan care continuă să crape. Oamenii subestimează adesea cât de multă latura emoțională se consumă pe iterații lente sau imprevizibile, în special atunci când o construcție durează ore și modul de eșec este vag.
Lista de verificare pentru evaluarea fluxului de instrumente:
• Viteza de iterație: sinteză + plasare/rutare + timp de bitstream pe hardware-ul dvs. CI, nu pe o mașină demo a furnizorului
• Comportamentul de închidere a temporizării: tendințe QoR, stabilitate între semințe și sensibilitate la mici modificări de constrângere
• Constrângeri și observabilitate: claritate SDC/XDC, acuratețea modelării ceasului, gestionarea căilor false/multicycle și cât de ușor se pot depista încălcările
• Instrumentație de debug: fluxul de inserție a analizorului logic, flexibilitatea sondelor, adâncimea de declanșare și cât de des trebuie să recompilați pentru a observa semnalele
• Potrivirea mediu: versiunile de SO acceptate, construcții fără cap, frecarea licențelor și cât de bine se potrivește cu fluxul de lucru al echipei dvs.
• Prietenie CI/VCS: reproducibilitate, ieșiri deterministe (atât cât permit instrumentele), scriptabilitate și durerea actualizării
Înainte de a vă angaja, efectuați un test de închidere a temporizării pe ceva reprezentativ (nu o jucărie). Includeți ceasurile reale, cel puțin o interfață de memorie externă și cel puțin un bloc I/O de mare viteză. Urmăriți:
• Timpul total de compilare per iterație
• Stabilitatea slack-ului pe câteva semințe
• Cât de repede poate un inginer să diagnosticheze primele trei probleme de temporizare fără cunoștințe tribale
Acest experiment tinde să producă un fel de claritate pe care listele de verificare funcționale nu o oferă. De asemenea, dezvăluie dacă echipa ta se va simți stabilă sau constant tensionată în timpul fazei de integrare.
Disponibilitatea și licențierea IP: Unde programările devin de obicei strânse
Chiar și atunci când resursele FPGA brute arată similare, programele depind adesea de realitățile IP. Aici echipele se pot simți surprinse: nucleul există, dar modelul de licență, efortul de integrare sau calitatea documentației îl transformă într-o muncă lentă.
Lista de verificare pentru IP și licențiere:
• Stive de protocol: PCIe, Ethernet MAC/PCS, JESD204, controlere DDR și orice interfețe de nișă pe care te bazezi
• Termeni de licență: legat de nod vs flotant, adăugiri de funcții, implicații pentru servere de build/CI și orice constrângeri de rulare sau desfășurare
• Proiecte de referință: numărul de lane-uri, planul de ceas, secvențierea resetului, arhitectura DMA și dacă se potrivește limitelor sistemului tău
• Orizont de suport: așteptări în materie de întreținere pe termen lung, frecvența patch-urilor și cum sunt trișate problemele
Un punct subtil pe care echipele îl învață pe calea grea: IP disponibil nu este același lucru cu IP drop-in. Demonstrațiile din laborator pot ascunde munca de integrare necesară pentru a atinge obiectivele tale de latență, tamponare și ceas. Planificarea timpului pentru validare și favorizarea IP-urilor cu documentație directă și exemple cunoscute-bune reduc adesea nivelul de stres ulterior, chiar dacă evaluarea inițială pare mai lentă.
Ecosistemul plăcii, riscul de activare și confortul platformelor cunoscute-bune
Alegerea FPGA-ului este legată de realitatea plăcii. În timpul activării, timpul dispare adesea în incertitudinea platformei mai degrabă decât în RTL: o constrângere de ceas ratată, o dependență de reset care nu a fost evidentă sau un canal de transceiver care este marginal doar la anumite temperaturi.
Lista de verificare a plăcii și platformei
• Plăci de evaluare și platforme de referință: disponibilitate, stabilitate a reviziilor și dacă proiectul este utilizat pe scară largă în teren
• Îndrumări pentru livrarea energiei: obiective PDN, abordare de decuplare, așteptări de secvențiere a magistralelor și presupuneri privind toleranța stivei
• Referințe pentru aranjamente de mare viteză: îndrumări pentru rutarea transceverelor, note de conformitate și stive dovedite
• Acces la depanare: stabilitatea JTAG, moduri de boot/config, suport pentru flash de configurare și vizibilitate în magistrale/ceasuri
• Responsivitatea suportului: canale ale furnizorului, raport semnal-zgomot al comunității și timpul de răspuns pentru problemele de unelte/IP
Utilizarea unei platforme adoptate pe scară largă cu proiecte de referință dovedite poate face activarea sistemului mai structurată și previzibilă. Această abordare ajută la mutarea depanării de la incertitudinea generală la verificarea măsurabilă pas cu pas, îmbunătățind eficiența dezvoltării.
Închiderea temporizării
Închiderea temporizării este locul unde diferențele între furnizori devin tangibile, mai ales când utilizarea crește și mai multe domenii de ceas interacționează. În această etapă, progresul proiectului poate rămâne stabil și previzibil sau poate deveni dificil atunci când modificările mici creează variații mari de temporizare.
• Scăparea de congestie: cum crește presiunea de rutare pe măsură ce utilizarea crește și unde începe să sări în sus
• Previzibilitatea Fmax: cât de des constrângerile moderate te apropie, comparativ cu necesitatea ajustărilor manuale intensive
• Calitatea raportării: dacă rapoartele de temporizare indică soluții acționabile, nu doar liste lungi de încălcări
• Robustetea: comportamentul în fața variațiilor PVT și a semințelor de implementare
Este în general mai sigur să presupui că efortul de închidere crește non-linear cu densitatea. După un anumit prag, o ajustare minoră în RTL poate transforma slack-ul din sănătos în fragil. Slack-ul arhitectural, pipeline-urile, planificarea selectivă a plăcii și alegerea unui dispozitiv cu spațiu pentru a respira depășesc adesea ajustările eroice ale constrângerilor pe care nimeni nu se bucură să le întrețină.
Compară piesa exactă
Specificațiile se schimbă de-a lungul generațiilor și în cadrul unei singure familii. Două piese cu nume similare pot avea comportamente suficient de diferite pentru a perturba un plan, mai ales odată ce ambalarea, gradul de viteză și maturitatea uneltelor intră în discuție.
• Grad de viteză: Fmax realizabil, comportamentul marjei de transceiver și diferențele modelelor de temporizare
• Pachet: numărul de I/O, amplasarea băncilor, impactul SI, comportamentul termic și constrângerile de asamblare
• Limitele funcțiilor SKU: blocuri dezactivate, capacitate redusă a transceiver-ului, proporții de memorie sau limitări ale protocolului pe anumite variante
• Maturitatea uneltei: nivelul de suport pentru dispozitive, frecvența lansărilor și dacă echipa ta poate standardiza pe o versiune stabilă a uneltei
Metoda practică de comparație:
• Modelele de temporizare ale furnizorului mapate pe ceasurile și interfețele tale reale
• Estimarea energiei folosind ratele de comutare realiste, cicluri de duty și setările de transceiver
• Constrângerile de pinout/bancă aliniate la cerințele plăcii tale și harta conectorului
• Versiunile uneltelor cu care organizația ta poate lucra pe durata de viață a produsului (inclusiv CI)
Un cadru de decizie care tinde să se mențină atunci când lucrurile devin stresante
Când presiunea programului crește, un cadru bazat pe măsurători ajută la evitarea pivotărilor impulsionate de regret. De asemenea, ajută echipa să se simtă mai stabilă, deoarece deciziile au o urmă scrisă legată de rezultatele observate, mai degrabă decât de optimism.
Ordine de selecție echilibrată:
1) Blochează cerințele măsurabile: resurse, I/O, memorie, latență și buget de putere/termal.
2) Prototipizează subsistemul cel mai dificil pentru fiecare candidat: comportamentul temporal + fluxul de depanare + bucla de construire/CI.
3) Evaluează maturitatea IP-ului și licențierea în raport cu planul tău de integrare, nu cu rezumatele de marketing.
4) Alege opțiunea cu marjă de siguranță și cu cea mai previzibilă buclă de iterație, mai degrabă decât cea care abia depășește minimurile.
Concluzia principală este că cel mai bun FPGA este rareori cel cu cele mai strălucitoare cifre de titlu. Echipele se mișcă de obicei mai repede și cu mai puțin încercând să se răzgândească atunci când platforma permite o convergență constantă, construcții repetabile și soluții întreținute pe durata de viață a produsului.
Instrumentele de bază

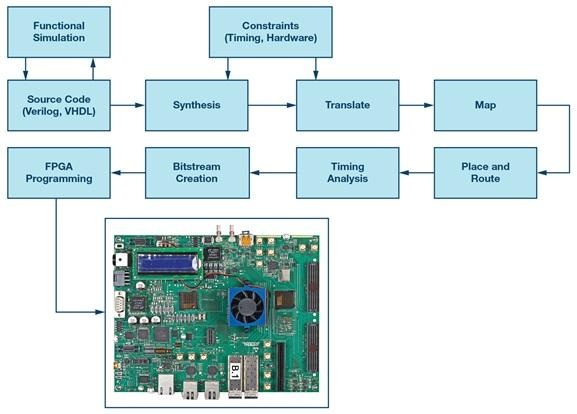
Rolul Vivado în fluxul de lucru FPGA
Vivado tinde să devină centrul operațional al unui proiect FPGA Xilinx, nu pentru că este glamoros, ci pentru că aici fiecare presupunere este testată împotriva realității instrumentului. Acesta preia HDL și constrângeri, produce o listă de rețea, execută plasarea și rutarea, în timp ce echilibrează regulile de sincronizare și proiectare fizică, apoi generează un flux de biți care programează dispozitivul.
O modalitate practică de a înțelege Vivado este de a-l considera ca două sisteme conectate: un sistem de conversie RTL la listă de rețea și un optimizer de implementare fizică. Aceasta explică de ce RTL-ul logic corect poate produce totuși rezultate instabile sau inconsistente atunci când constrângerile sunt incomplete, definițiile de ceas sunt inexacte sau structura proiectului creează dificultăți de rutare și sincronizare.
Cele mai multe proiecte urmează un pipeline familiar, chiar și atunci când detaliile diferă în funcție de familia de dispozitive și stilul de flux.
• Sinteza: traduce RTL într-o reprezentare la nivel de poartă și inferă structuri specifice dispozitivelor.
• Implementare: efectuează plasarea, rutarea și optimizarea bazată pe temporizare sub constrângeri fizice.
• Generarea fluxului de biți: emite imaginea de configurare și verifică implementarea rezultatului în raport cu constrângerile și regulile instrumentului.
Un program tinde să devină tensionat nu atunci când un flux de biți este produs o dată, ci atunci când echipa are nevoie ca fluxul de biți să se comporte ca o ieșire de încredere: rezultate similare între reconstrucții, margini de sincronizare care supraviețuiesc la viteza țintă și stabilitate când se fac editări mici ale RTL pentru corecții funcționale. Aici unde ceea ce s-a construit ieri nu mai este reconfortant.
Echipele care se mișcă mai repede în timp de obicei încetează să trateze rapoartele ca pe niște acte administrative și încep să le trateze ca pe dovezi inginerești. Atunci când artefactele de construire sunt colectate constant, discuțiile de proiect devin mai puțin emoționale și mai concrete, ceea ce este o ușurare când termenul limită se apropie.
• Rapoarte de sinteză/implementare: utilizare, primitive inferate, avertizări și rezumate structurale.
• Ieșiri de temporizare: WNS/TNS, puncte finale eșuate, trasee detaliate și rezumate de interacțiune a ceasului.
• Constrângeri XDC: ceasuri, reguli I/O, excepții și alocări de pini fizici.
• Puncte de control implementate (DCP): instantanee reproducibile care susțin iterații rapide și experimente controlate.
Un model care apare în munca reală este că un set de rapoarte ordonate și intern consistente prezice adesea un progres mai lin decât un singur banner verde „PASS”. Banner-ul poate ascunde fragilitatea; rapoartele de obicei nu o fac.
Instalare și configurare a mediului
O configurare care pur și simplu lansează GUI-ul este ușor de sărbătorit și ușor de regretat mai târziu. Configurările în care echipele au încredere sunt plictisitoare într-un mod bun: se comportă la fel sub automatizare, sunt consistente pe mașini și nu te surprind după o actualizare a instrumentului.
Alege ediția Vivado ML care corespunde țintelor tale de dispozitive, apoi activează doar familiile de dispozitive pe care intenționezi realmente să le construiești. Aceasta reduce utilizarea discului și timpul de indexare și, de asemenea, reduce șansele de erori accidentale de configurare între familii care pot irosi o după-amiază.
În echipele de dezvoltare multi-board, menținerea unei liste definite de dispozitive acceptate pentru fiecare proiect ajută la păstrarea dezvoltării mai controlate și consistente decât în dependență de orice instrumente sau piese care sunt instalate.
Ieșirile Vivado pot varia între versiuni deoarece algoritmii de plasare, rutare și temporizare evoluează, iar erorile sunt corectate (sau înlocuite cu erori diferite). Multe echipe obțin construcții mai calme prin fixarea unei versiuni de instrument pentru fiecare ramură de lansare și actualizându-se în pași planificați, mai degrabă decât să se lase să driftuie continuu.
Atunci când încearcă o versiune mai nouă, echipele compară adesea semnalele practice ale sănătății instrumentului înainte de a o adoptă ca nouă bază de referință: marje de sincronizare, schimbări de utilizare, delta de avertizare și orice mesaje noi de acoperire a constrângerilor. Timpul petrecut pentru a face această comparație este de obicei mai ușor decât a argumenta târziu în ciclu dacă sincronizarea a devenit brusc mai rea fără motiv.
Pentru construcțiile din linia de comandă, sistemele CI și serverele de construcție partajate, mediul de dezvoltare trebuie să se comporte în mod constant pe toate sistemele în loc să depindă de configurațiile individuale ale mașinilor.
• Scripturi de setări: sursați setările corecte ale instrumentului pentru ca căile, bibliotecile și dependențele de rulare să se rezolve în mod constant.
• Fluxuri conduse de Tcl: preferați construcțiile scriptate pentru execuții repetabile, raportare uniformă și integrare CI.
• Disciplina interfeței de construcție: mențineți intrările și ieșirile stabile astfel încât modificările să fie intenționate și revizibile.
Un flux comun de dezvoltare este de a finaliza mai întâi o construcție stabilă a GUI pentru a verifica designul, apoi de a face tranziția la un flux bazat pe Tcl astfel încât procesul de construcție să nu mai depindă de setările GUI, datele în cache sau diferențele dintre mașinile de dezvoltare.
Rapoartele pe care doriți să le citiți ca diagnosticare
Cele mai multe dintre momentele în care designul a eșuat nu sunt misterioase mult timp dacă rapoartele sunt citite ca o poveste despre ceea ce a crezut instrumentul. Avertizările, acoperirea constrângerilor și căile de sincronizare tind să documenteze modul de eșec la vedere, deși nu întotdeauna în cea mai prietenoasă ordine.
Echipele se îmbunătățesc cel mai rapid atunci când tratează ieșirile Vivado ca un ciclu de feedback zilnic în loc de ceva la care se deschide doar atunci când construcția se rupe.
Aceste rapoarte sunt adesea primul loc unde devierea intenției devine vizibilă, iar acest lucru poate fi ciudat de reconfortant: cel puțin problema este concretă.
• Utilizarea resurselor: LUT, FF, BRAM, DSP, URAM versus limitele dispozitivului și marja de manevră.
• Verificări de inferență: stiluri RAM neasteptate, lipsă de inferență DSP, mapare surprinzătoare a primitivului.
• Semne roșii structurale: plase cu mare dispersie, multiplexare largă, lanțuri combinate lungi.
• Avertizări: inferență de latch, gestionarea incompletă a sensibilității, logică neconectată sau tăiată.
Inferența de latch și căile combinate lungi neintenționate apar frecvent în practică. Instrumentul le va implementa fără plângeri, iar acest lucru poate părea înșelător atunci când sincronizarea mai târziu refuză să coopereze în moduri care par aleatorii până când sunt citite rapoartele căii.
Închiderea sincronizării devine mai puțin stresantă atunci când echipa știe ce optimizează instrumentul și de ce alege anumite compromisuri.
• Semnale de slack: WNS ca cea mai gravă încălcare singulară; TNS ca dispersia generală a încălcărilor.
• Descompunerea căii: unde se acumulează întârzierea (adâncimea logicii, rutare, sincronizare sau presupuneri de constrângere).
• Modelarea ceasului: dacă căile sunt analizate așa cum se intenționează, ignorate sau grupate incorect.
O lecție nuanțată pe care echipele experimentate o internalizează este că durerea de sincronizare este adesea o problemă de modelare a constrângerilor mai întâi și o problemă RTL pe locul doi. Când modelul de ceas este greșit, acesta poate petrece zile optimizând punctele finale greșite și încă poate părea că instrumentul nu ascultă.
Găurile de constrângere sunt un infractor repetat, parțial deoarece nu arată întotdeauna dramatic până când proiectul este avansat.
• Găuri în definiția ceasului: ceasuri primare lipsă sau incorecte.
• Găuri în ceasurile generate: ceasuri împărțite/înmulțite/transmise neîntrebate, forțând instrumentul să ghicească.
• Găuri în definiția I/O: constrângeri I/O lipsă care duc la presupuneri optimiste și ulterior la surprize la nivel de placă.
• Abuz de excepție: excepții lipsă sau excepții care sunt prea largi pentru a fi de încredere.
O obișnuință pragmatică este să tratați XDC ca o specificație vie, și nu ca un fișier de corectare. Atunci când sunt introduse excepții, echipele care dorm mai bine tind să le mențină înguste, explicate și legate de o relație de sincronizare reală, mai degrabă decât să le folosească pentru a liniști încălcările care merită o examinare.
Strategia de constrângere XDC
Fișierul XDC este locul unde intenția designului este forțată să devină explicită. Când este puțin greșit, comportamentul de sincronizare rezultat poate părea haotic, chiar dacă instrumentul este perfect determinist.
Definiți ceasurile explicit, apoi verificați dacă instrumentul le-a propagat așa cum vă așteptați. Problemele modelului de ceas sunt adesea mai ușor de corectat decât problemele mai profunde de sincronizare arhitecturală, făcându-le mai simple de rezolvat în timpul analizei și depanării sincronizării.
• Ceasuri primare: definite din pini sau din ieșirile MMCM/PLL.
• Ceasuri generate: definite pentru domenii împărțite, înmulțite sau transmise.
• Relații asincrone: declarate prin grupuri de ceasuri sau relații explicite.
Pe plăci reale, un ceas generat omis poate produce o imagine de sincronizare înșelătoare care consumă zile, mai ales când instrumentul optimizează către puncte finale care nu au fost niciodată menite să fie analizate împreună.
Constrângerile I/O modelează presupunerile electrice și de temporizare utilizate de instrument, și pot determina în liniște dacă succesul din laborator se transformă în „succesul sistemului”.
• Standardele electrice: standarde și tensiuni I/O aliniate cu designul plăcii.
• Disciplina pin-urilor: blocarea locațiilor pin-urilor odată ce maparea s-a stabilizat pentru a evita fluctuațiile.
• Temporizarea interfeței: întârzieri de intrare/ ieșire care reflectă dispozitivul extern, nu implicitățile instrumentului.
O dezamăgire familiară în etapele târzii este: A respectat temporizarea în construcție, dar interfața eșuează sub trafic real. Acest rezultat se învârte adesea în jurul presupunerilor I/O implicite care nu au fost niciodată actualizate pentru a se potrivi bugetului de temporizare al plăcii și dispozitivului extern.
Excepțiile pot clarifica intenția, și de asemenea pot crea o iluzie fragilă de progres dacă supraviețuiesc justificării lor originale.
• Cărți false: utilizate doar atunci când calea nu face parte în mod real din temporizarea funcțională.
• Cărți multicioc: utilizate doar atunci când relația de captare se întinde cu adevărat pe mai multe cicli și este documentată.
• Igiena excepțiilor: menține setul mic, revizuiește-l după schimbări majore de RTL/pipeline și pensionează intrările învechite.
Unele dintre cele mai costisitoare erori de temporizare provin din excepții care au fost corecte odată, apoi au devenit silențios inexacte după o schimbare de pipeline. Instrumentul va respecta fără plângeri, ceea ce este exact ceea ce face acest mod de eșec atât de neplăcut.
Modele tipice de eșec și cum să le rezolvăm eficient
Anumite probleme se repetă în cadrul proiectelor, indiferent dacă aplicația este networking, viziune, control sau accelerație. Recunoașterea timpurie a modelului tinde să reducă sarcina emoțională a depanării, deoarece echipa poate trece de la „de ce se întâmplă asta” la „ce manual se aplică”.
Această situație se simte adesea ca și cum instrumentul este încăpățânat, dar cauzele fundamentale sunt de obicei urmărite.
• Adâncimea combinațională: căi lungi cauzate de lipsa sau insuficiența pipelinării.
• Presiunea fanout: rețele de control cu fanout mare care beneficiază de replicare, bufferizare sau restructurare.
• Modelarea constrângerilor: definiții de ceas sau relații care caracterizează greșit ceea ce ar trebui analizat.
O secvență care tinde să funcționeze bine este: validează modelul de temporizare (ceasuri și relații), concentrează-te pe cele mai slabe puncte de eșec mai întâi, apoi extinde-te la schimbări arhitecturale doar dacă dovezile de cale susțin acest lucru.
Aceasta este una dintre cele mai demoralizante experiențe în muncă cu FPGA, în principal pentru că se simte ca și cum realitatea ar fi nedreaptă. De obicei, este doar că simularea nu a stresat aceleași moduri de eșec.
• Comportamentul CDC/reset: secvențierea resetului și trecerile dintre domenii care simularea rareori le exercită realist.
• Presupunerile I/O: I/O necontrolate sau greșit controlate care produc interfețe reale marginale.
• Comportamentul de inițializare: dependența de valori inițiale care nu se mapează curat la comportamentul de activare a dispozitivului.
Equipele care devin mai stabile aduc strategia CDC și de resetare în discuția de design devreme, tratându-le ca parte a arhitecturii de design mai degrabă decât ca o fază de curățare după ce „logica reală” este finalizată.
Această problemă este comună pentru că plasarea și rutarea răspund brusc la schimbările de structură a rețelei, chiar și atunci când schimbarea funcțională pare minoră.
• Sensibilitatea rețelei: refactorizări mici pot altereze deciziile de ambalare, plasare și congestionarea rutării.
• Deriva constrângerilor: schimbări mici în XDC (sau acoperire lipsă) pot amplifica variația de temporizare.
• Obiceiuri de mitigare: implementare incrementală, păstrarea ierarhiei selective și constrângeri stabile.
Când echipele adoptă aceste obiceiuri de mitigare, iterația tinde să pară mai previzibilă, ceea ce reduce tentația de a îngheța designul prematur din frica de a rupe din nou temporizarea.
Considerații privind licențierea
Licențierea tinde să devină o conversație atunci când un proiect se lovește de limitele de acoperire a dispozitivelor sau când funcții avansate sunt necesare pentru un anumit flux de lucru.
• Standard: se aliniază adesea cu plăcile de învățare de intrare și medii și fluxurile de bază.
• Întreprindere: se aliniază adesea cu suportul mai larg al dispozitivelor și a capacităților avansate.
Pentru echipe, licențele flotante susținute de un server de licențe sunt adesea mai ușor de scalat decât licențele legate de noduri, mai ales atunci când construcțiile rulează pe mașini partajate, servere dedicate de construcție sau CI runners. Multe echipe preferă să alinieze licențierea cu foaia de parcurs a dispozitivului mai devreme decât mai târziu, deoarece surprizele legate de licențiere au obiceiul de a apărea atunci când schimbarea dispozitivelor este deja costisitoare și politică dificilă.
Un ciclu de inginerie constant tinde să prezică progrese mai constante decât orice optimizare inteligentă unică: menține constrângerile aliniate cu realitatea, citește rapoartele în mod rutinier (chiar și atunci când ai prefera să nu), repară cauzele fundamentale în loc să calmezi simptomele și menține construcțiile reproducibile. Când acest ciclu este stabilit, Vivado pare mai puțin ca o cutie neagră și mai mult ca un panou de control, iar închiderea temporizării se transformă dintr-o presiune de ultim moment într-un lucru pe care echipa îl poate gestiona deliberat.
Portofoliul și Ecosistemul Xilinx

Alegerea între dispozitivele Xilinx tinde să decurgă mai lin atunci când punctul de plecare este integrarea din jur (procesoare, interfețe de memorie, cale de boot și dependențe la nivel de placă), nu doar o comparație a totalurilor brute de LUT-uri. Această formulare se potrivește de obicei cu modul în care programele reale și riscurile reale apar.
Un FPGA discret tinde să se potrivească atunci când echipa dorește o proprietate completă a arhitecturii plăcii și încărcătura se îndreaptă spre un comportament hardware determinist cu o suprafață minimă de software. Un SoC de clasă Zynq tinde să se potrivească atunci când proiectul beneficiază de un CPU care se află aproape de logica de accelerare, astfel încât controlul și calea de date să poată evolua împreună fără a transforma placa într-o negociere multi-chip. Un modul de tip Kria SOM tinde să se potrivească atunci când planul este să avanseze rapid și să reducă incertitudinea la pornirea plăcii tratând calculul, memoria și stocarea de boot ca pe un bloc de construcție pre-validate.
FPGA discret tinde să se potrivească pentru:
• control maxim al designului plăcii
• conducte deterministe cu o dependență software limitată
SoC Zynq tinde să se potrivească pentru:
• cuplaj strâns CPU+accelerator
• calcul/unificat control pe un singur dispozitiv
• evoluție HW/SW iterativă
Kria SOM tinde să se potrivească pentru:
• timp mai scurt până la produs
• expunere redusă la nivel de placă prin utilizarea unui subsistem de calcul validat
FPGA-urile obișnuite adesea se adaptează bine atunci când problema este determinată de presiunea de închidere a temporizării, nevoile neobișnuite de I/O sau conductele de streaming care se comportă cel mai bine ca hardware cu funcție fixă. Latenta predictibilă și căile de date structurate îmbunătățesc adesea controlul, verificarea și depanarea, mai ales când arhitectura rămâne bine organizată.
Dispozitivele autonome apar frecvent în:
• interfațarea senzorilor
• controlul motoarelor
• procesarea pachetelor cu rată moderată
• punerea în legătură a protocoalelor
În teren, o sursă recurentă de frustrare nu este RTL-ul în sine, ci obligațiile din jurul plăcii care apar în liniște și apoi domină calea critică. Căile de alimentare, strategia de configurare și boot, generarea ceasului, aranjarea memoriei externe (când este prezentă) și accesul la depanare pot deveni constrângerile care conturează întregul produs. O regulă practicală este că cu cât povestea memoriei externe este mai simplă și cu atât sunt mai puține transceivere de mare viteză implicate, cu atât experiența FPGA-ului autonom devine mai satisfăcătoare. De îndată ce DDR extern și fluxurile de boot în mai multe etape devin inevitabile, atractivitatea integrării unui SoC sau a unui modul începe să se simtă mai puțin ca o caracteristică și mai mult ca o ușurare.
Familiile optimizate din punct de vedere al costului își propun în general o combinație măsurată de LUT-uri, BRAM și DSP sub bugete de putere restricționate. Acestea apar frecvent în produsele în care echipa de inginerie dorește capabilități rezonabile fără a plăti taxa de placă și termică care vine cu interfețe extreme.
Zonele comune de aterizare includ:
• control încorporat
• agregare I/O de medie gamă
• procesare de semnal de viteză moderată
Avantajul nu este doar la nivel de preț pe unitate, echipele apreciază adesea că aceste părți fac mai ușor să rămână în limitele termice fără a recurge la soluții agresive de disipare a căldurii și pot împiedica placa să evolueze într-un proiect de circuit de mare viteză. În același timp, construcțiile din teren predau frecvent o lecție ușor inconfortabilă: un dispozitiv de cost mai mic poate genera cheltuieli totale mai mari dacă forțează compromisuri de design în etapele finale. Când marja de temporizare este subțire, ajustările mici, o schimbare standard de I/O, o modificare a rutării ceasului, o schimbare a planului de etaj pot duce la agitația verificării și anxietatea legată de program. Pentru aceste dispozitive, echipele economisesc de obicei timp stabilind planificarea domeniului de ceas, strategia CDC și comportamentul de resetare devreme, mai degrabă decât sperând că optimizările minore de ultim moment vor salva planul.
SoC Zynq
Dispozitivele Zynq combină procesarea ARM cu logica programabilă, ceea ce permite proiectului să se împartă în software de plan de control și accelerare a planului de date într-un mod care se simte natural pentru multe echipe de produse. Acest lucru face mai mult decât să îmbunătățească confortul, transformă fluxul de lucru. Echipelor le poate fi util să înceapă cu un referințial software-primar pentru încrederea funcțională, apoi să migreze căile fierbinți în hardware pe măsură ce cerințele de debit și latență devin mai puțin negociabile.
În implementările care îmbătrânesc bine, CPU-ul rareori „înlocuiește” hardware-ul, tinde să stabilizeze produsul. Procesorul ajunge adesea să gestioneze configurația, telemetria, actualizările de teren, politica de securitate și conectivitatea de tip edge, în timp ce materialul funcționează cu canale de tip determinist. Acea separare poate fi reconfortantă din punct de vedere emoțional pentru mentenanți: software-ul absoarbe schimbarea, hardware-ul rămâne stabil, iar lansările par mai puțin riscante.
CPU-ul poartă în mod obișnuit:
• configurație
• telemetrie
• actualizări
• politică de securitate
• conectivitate de tip edge
Materialul poartă în mod obișnuit:
• canale de streaming deterministe
• acceleratoare stabile
• căi de date sensibile la latență
Pe măsură ce densitatea de calcul crește și interfețele devin mai solicitante, piesele de tip Zynq UltraScale+ reduc complexitatea plăcii și sistemului prin apropierea nucleelor CPU, a controlerelor DDR și a interconexiunilor de mare lățime de bandă de material. Acest lucru devine atractiv în proiectele care necesită atât determinism în timp real, cât și un mediu software capabil, mai ales când sarcina de lucru este un amestec mai degrabă decât un singur nucleu curat.
Cazurile de utilizare frecvente includ:
• analize de tip edge
• fuziune multi-senzorială
• canale mixte în timp real plus AI
Un detaliu pe care echipele experimentate învață să-l respecte este că „mai mult material” nu se transformă automat în „mai multă performanță livrată.” Proiectele adesea se ciocnesc de plafoanele de lățime de bandă a memoriei înainte de a rămâne fără DSP-uri sau LUT-uri. Proiectele care decid asupra topologiei DMA, strategiei de bufferizare și a așteptărilor de coherență a cache-ului devreme tind să atingă performanțe stabile cu mai puțin haos decât proiectele care amână deciziile de mișcare a datelor până la integrarea târzie.
Partajarea rar se referă la faptul dacă ceva ar putea fi accelerat, ci mai mult la faptul dacă accelerarea merită efortul de verificare, complexitatea driverului și a timpului de execuție și cât de des se așteaptă să se schimbe logica. Echipele simt adesea un război de forțe aici: împingerea prea mult în hardware poate încetini iterația, în timp ce lăsarea prea mult pe CPU poate lăsa obiectivele de throughput perpetuu aproape atinse.
Sarcinile de lucru care rămân frecvent pe CPU mai mult timp decât se aștepta includ:
• logică în schimbare rapidă
• comportament complex bazat pe parsare
• caracteristici cu cicluri rapide de iterație
Sarcinile de lucru care recompensează adesea accelerarea timpurie a materialului includ:
• algoritmi stabili
• nuclee dense în calcul
• căi de date prietenoase cu streaming-ul
Un model pragmatic este să începi cu o mică secțiune de la un capăt la altul, adesea un simplu DMA loopback plus un accelerator minim, înainte de a construi întreaga setare a caracteristicilor. Acest prototip limitat tinde să scoată la lumină problemele de integrare care altfel apar târziu și costisitor: comportamentul întreruperilor, alinierea buffer-ului, costul întreținerii cache-ului și plafoanele de throughput care apar doar sub o sarcină susținută.
Kria SOM-uri și platforme de tip modul
Kria SOM-urile împachetează calculul, memoria și stocarea pentru boot într-un subsistem gata, mutând efortul de la aducerea plăcii în funcțiune la ingineria aplicației. Echipele adesea preferă această abordare deoarece conține incertitudine: integritatea semnalului, rutarea DDR, secvențarea puterii și fiabilitatea boot-ului sunt deja validate, ceea ce poate face ca demo-urile timpurii să pară mai puțin fragile și planificarea să pară mai puțin speculativă.
Abordarea tinde să funcționeze în special bine când diferențierea se află în algoritmi, topologia I/O și fiabilitatea implementării, mai degrabă decât într-o placă de calcul personalizată. De asemenea, poate reduce fricțiunea între echipe: munca de hardware, firmware și aplicație poate avansa în paralel cu mai puține momente de „blocat de aducerea în funcțiune”.
Integrarea validată a SOM-ului acoperă în mod obișnuit:
• integritatea semnalului
• rutarea DDR
• secvențarea puterii
• fiabilitatea boot-ului
Echipele pot reorienta efortul pe:
• diferențierea plăcii purtătoare
• integrarea firmware-ului
• comportamentul aplicației
• întărirea implementării
Un SOM poartă adesea un cost per unitate mai mare decât o placă complet personalizată, totuși costul total al programului poate scădea în continuare când programările sunt strânse sau riscul de randament al fabricării este incomod. Câștigul mai puțin evident este predictibilitatea ciclului de viață: cu un modul, calculul poate fi uneori tratat ca un element interschimbabil între variante de produse, reducând volatilitatea redesignului atunci când cerințele se schimbă în cursul procesului.
Cel mai liniștitor pas este să se valideze devreme că spațiul termic, expunerea I/O și lățimea de bandă a memoriei SOM-ului se potrivesc de fapt sarcinii de lucru intenționate, mai degrabă decât a se baza pe o citire a fișei de specificații. Dacă aplicația ajunge să fie limitată de lățimea de bandă, reglarea în stadiile târzii tinde să se simtă ca împingerea unei uși încuiate, nepotrivirile dintre cererea acceleratoare și subsistemul de memorie al modulului dominând pur și simplu.
Verificările de potrivire timpurii includ în mod obișnuit:
• envelopă termică
• I/O expus
• lățimea de bandă susținută a memoriei versus cerințele sarcinii de lucru
Implementarea AI în ecosistem
Vitis AI ajută la conversia modelelor antrenate în designuri de inferență bazate pe FPGA, folosind formate de precizie mai mică, adesea INT8, și compilându-le pentru arhitecturi de tip DPU. Aceasta confirmă rapid dacă un model poate funcționa pe platforma FPGA. Performanța reală, totuși, depinde adesea de proiectarea sistemului înconjurător, în special de mișcarea datelor și gestionarea memoriei.
Debitul end-to-end este guvernat, de obicei, de cât de constant poate sistemul să alimenteze DPU-ul. Strategia de grupare, aranjamentul tensorilor, programarea DMA, dublarea buffer-ului și plasarea memoriei decid adesea FPS-ul livrat mai mult decât performanța computațională de vârf. Echipele care tratează DPU-ul ca un consumator constant de streaming, cu buffere atent aranjate, tind să evite dezamăgirea comună a TOPS teoretice impresionante, dar cu rezultate dezamăgitoare la nivel de sistem.
Butoanele de modelare a performanței includ, de obicei:
• strategia de grupare
• aranjamentul tensorilor
• programarea DMA
• dublarea buffer-ului
• plasarea memoriei
În desfășurări, alegerile minore de implementare se compun în moduri care pot fi greu de prezis din microbenchmark-uri de laborator. Bufferele nealiniate pot reduce în liniște lățimea de bandă efectivă. Menținerea excesivă a memoriei cache poate consuma timp CPU și crea jitter. Pipele grele de copiere pot șterge o mare parte din beneficiul obținut din cuantizare. O abordare bine fundamentată este să măsori lățimea de bandă și latența la fiecare limită și apoi să concentrezi eforturile pe limita care este momentan cea mai strânsă.
Limitele utile de măsurare includ:
• senzor la DDR
• DDR la accelerator
• accelerator la post-procesare
Un model mental util este să vezi pipeline-ul AI ca o rețea de flux restricționată. Cu această cadrul, selecția dispozitivului devine mai puțin despre vânătoarea celui mai mare număr de calcul și mai mult despre alegerea opțiunii care relaxează cel mai dominant gât de sticlă și menține comportamentul pipeline-ului predictibil.
Ecosistem și facilitare
Ecosistemul Xilinx se extinde dincolo de siliciu la facilitarea înconjurătoare care menține echipele în mișcare: lanțuri de instrumente, IP, designuri de referință, plăci partener și resurse de formare. În medii academice, Programul Universitar este adesea apreciat deoarece reduce durerea de configurare recurentă, accesul la unelte, disponibilitatea plăcilor și structura laboratorului, astfel încât progresul timpuriu este mai puțin probabil să se blocheze din cauza problemelor de mediu, mai degrabă decât din cauza învățării ingineriei efective.
Componentele ecosistemului includ:
• lanțuri de instrumente (Vivado, Vitis)
• cataloage IP
• designuri de referință
• plăci partener
• programe de formare
• resurse ale Programului Universitar
Odată ce frecarea în recrutare este redusă, învățăceii pot să-și petreacă energia pe obiceiurile care se traduc direct în muncă profesională: rutine de închidere a timpului, disciplină de pipelining, strategie de verificare și judecată de co-proiectare hardware/software. Aceste abilități tind să își arate valoarea în timpul integrării, când rezultatele sunt modelate mai mult de viteza de iterație și coeziunea sistemului decât de un benchmark izolat al nucleului.
Abilitățile transferabile includ:
• obiceiuri de închidere a timpului
• disciplină de pipelining
• strategie de verificare
• co-proiectare hardware/software
Un principiu de selecție care rămâne constant în întreaga gamă
O abordare de selecție de încredere pornește de la constrângerile sistemului și nu de la nivelurile de marketing. Echipele obțin, în general, decizii mai clare atunci când își notează obiectivele de operare și realitățile proiectului din timp, apoi aleg nivelul de integrare, FPGA, Zynq SoC sau SOM, care reduce cele mai mari surse de incertitudine pentru programul lor specific. Acest lucru tinde să producă alegeri care se simt mai bine luni mai târziu, când integrarea și viteza de iterație contează mai mult decât o comparație de piese pe hârtie.
Constrângerile de definit devreme includ:
• obiective de latență
• necesități de lățime de bandă susținută
• cerințe de interfață
• limite termice
• cadenta actualizării
• bugetul de verificare
În multe programe, opțiunea care menține mișcarea datelor simplă și bucla de dezvoltare strânsă ajunge să fie cea care îmbătrânește cel mai bine, chiar dacă prețul său pe unitate nu este cel mai atractiv la prima vedere.
Concluzie
Învățarea designului FPGA Xilinx devine mai ușoară atunci când fiecare proiect urmează un proces stabil și repetabil. Rezultatele puternice depind de HDL curat, constrângeri corecte, verificări atente ale timpului, simulare și validare hardware real. Începând cu designuri simple și dezvoltând obiceiuri bune de depanare, începătorii pot dezvolta abilități FPGA fiabile pentru sisteme digitale mai avansate.
Întrebări frecvente [FAQ]
1. De ce se confruntă de obicei începătorii FPGA cu dificultăți chiar și atunci când codul lor HDL pare logic corect în simulare?
Multe probleme timpurii ale FPGA nu sunt cauzate de RTL în sine, ci de discrepanta dintre presupunerile de simulare și comportamentul fizic al hardware-ului. Simularea ascunde de obicei probleme legate de constrângerile ceasului, sincronizarea resetării, standardele I/O, metastabilitatea și închiderea temporizării. Un design poate simula perfect, în timp ce eșuează pe hardware, deoarece instrumentele FPGA interpretează ceasurile diferit, constrângerile sunt incomplete sau intrările asincrone sunt gestionate incorect.
2. De ce constrângerile temporale sunt considerate o parte esențială a designului FPGA în loc de un ultim pas de optimizare?
Constrângerile temporale definesc modul în care instrumentele FPGA interpretează ceasurile, relațiile temporale I/O, ceasurile generate și domeniile asincrone. Fără constrângeri precise, Vivado poate optimiza designul folosind presupuneri incorecte, ceea ce duce la rapoarte temporale înșelătoare și comportamente instabile ale hardware-ului. Multe eșecuri FPGA apar chiar și atunci când logica în sine este corectă, deoarece ceasurile nu au fost declarate corespunzător, sincronizarea I/O a fost ignorată sau excepțiile au fost aplicate prea larg. În practică, constrângerile acționează ca o descriere formală a intenției designului, permițând instrumentelor să construiască hardware care se potrivesc comportamentului electric real.
3. De ce depanarea FPGA necesită adesea atât simulare, cât și instrumente pe cip, cum ar fi ILA?
Simularea este extrem de eficientă pentru detectarea erorilor funcționale, dar nu poate reproduce complet efectele hardware-ului din lumea reală, cum ar fi jitter-ul, intrările asincrone, întârzierea la nivel de placă, metastabilitatea și variația la pornire. Instrumentele de depanare pe cip, cum ar fi Analizatorul Logic Integrat (ILA), oferă vizibilitate asupra semnalelor interne ale FPGA în timp ce sistemul funcționează în condiții reale. Acest lucru permite capturarea tranzițiilor de stare reale, comportamentul FIFO, strângerile de mâini și relațiile temporale direct în interiorul dispozitivului. Combinarea simulării cu depanarea ILA creează o înțelegere mai completă a motivului pentru care hardware-ul s-a abătut de la comportamentul așteptat.
4. De ce inginerii FPGA experimentați preferă fluxuri de lucru disciplinate și repetabile în loc de a schimba constant setările proiectului?
Fluxurile de lucru repetabile reduc incertitudinea și fac mai ușor de izolat eșecurile. Folosind aceeași placă de dezvoltare, structură de ceas, strategie de resetare și șablon de proiect, inginerii pot să se concentreze pe logica care este dezvoltată în loc să depaneze repetat mediul însăși. Proiectele FPGA implică multe variabile interacționante, inclusiv constrângeri, temporizare, comportament de sinteză și configurare la nivel de placă. Când prea multe variabile se schimbă simultan, depanarea devine imprevizibilă și epuizantă emoțional. Fluxurile de lucru stabile îmbunătățesc încrederea, deoarece modificările pot fi urmărite până la decizii specifice de design, mai degrabă decât la diferențe de mediu necunoscute.
5. De ce designul hardware-ului FPGA este fundamental diferit de programarea software-ului tradițional?
Software-ul execută instrucțiuni secvențial, în timp ce hardware-ul FPGA funcționează prin structuri logice concurente care rulează simultan. HDL descrie comportamentul fizic al hardware-ului, mai degrabă decât fluxul de execuție procedural. Începătorii își dau adesea seama de comportamentele asemănătoare software-ului, apoi devin confuzi atunci când mai multe blocuri hardware reacționează la aceeași margine de ceas în paralel. Designul FPGA pune, așadar, accent pe pipeline-uri, relații temporale, sincronizare, maparea resurselor și comportamentul domeniilor de ceas, în loc de ordinea instrucțiunilor de una singură. Înțelegerea concurenței este una dintre cele mai importante schimbări mentale în ingineria FPGA.
6. De ce schimbările mici în RTL pot provoca brusc probleme majore de închidere temporară în proiectele FPGA?
Comportamentul temporar al FPGA depinde în mare măsură de plasare, congestie de rutare, distribuție, relații de ceas și utilizarea resurselor fizice. Chiar și modificările mici în RTL pot altera modul în care instrumentele de sinteză și rutare maparea logică în întreaga dispozitiv. O schimbare aparent inofensivă poate crește presiunea de rutare, lunge căile combinatorice sau afecta deciziile de plasare în moduri care reduc semnificativ marjele temporale. Această sensibilitate devine mai severă pe măsură ce utilizarea crește, în special atunci când proiectele se apropie de limitele de rutare sau de ceas.
7. De ce proiectele FPGA devin frecvent constrânse de realitățile de nivel de placă în loc de complexitatea RTL singură?
Pe măsură ce sistemele FPGA cresc, provocările legate de secvențierea energiei, aranjamentul DDR, generarea ceasurilor, comportamentul termic, integritatea semnalului și rutarea transceiver-ului domină adesea timpul de dezvoltare. RTL-ul poate funcționa corect în timp ce infrastructura hardware înconjurătoare introduce instabilitate sau eșecuri de integrare. Inginerii descoperă frecvent că deciziile de design ale plăcii, secvențierea resetării și comportamentul interfeței de memorie modelează succesul general al proiectului mai mult decât HDL-ul în sine. Acest lucru este deosebit de adevărat în sistemele de mare viteză care utilizează memorie DDR externă și interfețe SERDES.
8. De ce multe echipe FPGA evaluează lanțurile de instrumente cu aceeași seriozitate ca hardware-ul FPGA în sine?
Toolchain-ul FPGA afectează direct timpul de compilare, stabilitatea închiderii temporale, eficiența depanării, integrarea CI și productivitatea generală a ingineriei. Rezultatele de implementare lente sau inconsistente pot crește dramatic timpul de iterație și presiunea asupra programului. Echipele evaluează adesea calitatea sintezei, claritatea raportului de timp, instrumentele de depanare și reproducibilitatea înainte de a se angaja pe o platformă. În medii de dezvoltare reale, construcțiile previzibile și închiderea temporală stabilă contează adesea mai mult decât specificațiile FPGA izolate de prima pagină.
9. De ce reduc platformele Zynq SoCs și Kria SOM complexitatea integrării comparativ cu FPGAs autonome?
SoC-urile Zynq combină procesoare ARM și logică programabilă într-un singur dispozitiv, simplificând comunicarea dintre accelerarea software și hardware. Kria SOM-urile merg mai departe prin integrarea memoriei, stocării pentru boot, secvenței de alimentare și hardware-ului validat într-un modul pre-certificat. Aceste abordări reduc riscurile asociate cu rutarea DDR, fiabilitatea boot-ului, proiectarea alimentării și punerea în funcțiune a plăcii. Ca rezultat, echipele se pot concentra mai mult pe comportamentul aplicațiilor și mai puțin pe provocările de integrare a hardware-ului la un nivel inferior.
10. De ce depinde implementarea cu succes a AI-ului bazat pe FPGA într-o măsură mare de mișcarea datelor și nu doar de performanța acceleratorului?
Acceleratoarele AI, cum ar fi DPU-urile, pot oferi un debit teoretic de calcul ridicat, dar performanța în lumea reală devine adesea limitată de lățimea de bandă a memoriei, programarea DMA, gestionarea buffer-elor și eficiența mișcării tensorilor. Pipelines de date slab optimizate pot înfometa acceleratorul și pot reduce dramatic FPS-ul efectiv, în ciuda capabilităților de calcul puternice. Prin urmare, sistemele AI bazate pe FPGA se concentrează foarte mult pe double-buffering, topologia DMA, strategia de grupare, amplasarea memoriei și fluxul de date susținut între senzori, memoria DDR, acceleratoare și etapele de post-procesare.
Blog înrudit
-
Câte zerouri într -un milion, miliarde, trilioane?
![Câte zerouri într -un milion, miliarde, trilioane?]()
2024/07/29
Milioane reprezintă 106, o cifră ușor de înțeles în comparație cu articolele de zi cu zi sau cu salariile anuale. Miliarde, echivalent cu 109, ... -
Fisa de date IRLZ44N MOSFET, circuit, echivalent, pinout
![Fisa de date IRLZ44N MOSFET, circuit, echivalent, pinout]()
2024/08/28
IRLZ44N este un MOSFET de canal N-canal utilizat pe scară largă.Renumit pentru capacitățile sale excelente de comutare, este foarte potrivit pentr... -
Temperatura bateriei prea scăzută, încărcarea s -a oprit.Cum să -l rezolvi?
![Temperatura bateriei prea scăzută, încărcarea s -a oprit.Cum să -l rezolvi?]()
2024/10/6
Problemele de încărcare a bateriei pentru telefonul mobil sunt comune, dar pot fi gestionate eficient.Temperatura joacă un rol important în eficie... -
BC547 Ghid cuprinzător al tranzistorului
![BC547 Ghid cuprinzător al tranzistorului]()
2024/07/4
Tranzistorul BC547 este utilizat în mod obișnuit într -o varietate de aplicații electronice, de la amplificatoare de semnal de bază la circuite o... -
Ghid cuprinzător pentru SCR (redresor controlat de siliciu)
![Ghid cuprinzător pentru SCR (redresor controlat de siliciu)]()
2024/04/22
Redarele controlate de siliciu (SCR) sau tiristori joacă un rol pivot în tehnologia electronică a puterii, datorită performanței și fiabilităț... -
LR621, SR621SW, 364, AG1 Echivalenți și înlocuitori ai bateriei AG1
![LR621, SR621SW, 364, AG1 Echivalenți și înlocuitori ai bateriei AG1]()
2024/07/15
Bateriile cu butoane LR621 și SR621SW sunt predominante în dispozitive electronice compacte, precum ceasuri, jucării mici, calculatoare și tastele... -
Un ghid complet pentru multiplexori și rolul lor în sistemele digitale
![Un ghid complet pentru multiplexori și rolul lor în sistemele digitale]()
2025/09/20
Multiplexoarele sunt componente în sisteme digitale, concepute pentru a canaliza semnale de intrare multiple într -o singură linie de ieșire folos... -
Fundamentele circuitelor Op-Amp
![Fundamentele circuitelor Op-Amp]()
2023/12/28
În lumea complexă a electronicelor, o călătorie în misterele sale ne conduce invariabil la un caleidoscop al componentelor circuitului, atât raf... -
Compararea diferențelor și aplicațiilor NMOS și PMOS
![Compararea diferențelor și aplicațiilor NMOS și PMOS]()
2024/11/15
Înțelegerea diferențelor dintre tranzistoarele NMOS și PMOS este importantă în proiectarea circuitelor eficiente.NMOS (N-Type Metal-Oxid-Semomon... -
Comparație CR2450 vs CR2032: Tot ce trebuie să știți
![Comparație CR2450 vs CR2032: Tot ce trebuie să știți]()
2025/09/15
Baterii cu buton, cum ar fi CR2450 și CR2032, alimentează multe electronice de zi cu zi, de la ceasuri și telecomenzi la dispozitive medicale și i...










Piese Hot
- HMK212B7104MGHT
- STM32F103C6U6A
- UAA2080H
- K4T1G164QG-BCF8
- HYB18H512321AF-14
- OP275GSZ
- EPF6016AQC208-2N
- FF300R06KE3
- 2225WC332KATBE
- DE28F800F3B125
- GAL20V8B-15LJNI
- SN75LBC173DRG4
- LDLN015PU18R
- AT49LV002-90TC
- R177D019FNR
- CY28RS4800XCT
- C1005X5R1H102M050BA
- SP3220EEA-L
- 12065A220KAT4A
- ST16C2552CJ44F
- CC0201CRNPO9BN4R3
- SST39VF1601C-70-4C-EKE
- SP208ECT-L/TR
- CY62147DV30LL-55ZSXIT
- C2012X8R1C105M125AB
- 06035A560JAT4A
- TAP224K050CRW
- CC0805JRNPO0BN100
- LTC2640AITS8-LM12#TRPBF
- GRM1556R1H1R9CZ01D
- MIC2179-5.0BSM
- MT48LC32M8A2P-75D
- 08052C102J4T2A
- PIC16F873-20/SP
- ISPLSI2032A-80LTN44
- RTS5170-GRT
- GRM1887U1H7R5DZ01D
- GTL2002DP
- IPB60R125CP
- LM7705MME/NOPB
- SSL4101T/1
- MSP430G2955IRHA40R
- T491D475K035ATZQ01
- VI-J13-IZ
- S34ML01G200BHV000
- SO63-4-55-22-90
- A6628EDT
- ATF1502SE-7JC44
- 5AGTFD7K3F40I3G
- MAX456XQH